给博客文章添加了 TOC
给博客文章添加了 TOC
TOC 即目录(Table of Contents),本身并不存在于 CommonMark 标准中,却可以帮助读者快速地了解这篇文章的大致结构,因而得到了广泛的应用。博客之前一直没有正经的侧边栏 TOC 支持,经过几番努力,终于在今日加上了。总体体验还不错(虽然有些小问题,我希望没人能发现)。本文将详细描述给博客加上 TOC 的具体方案和过程。
TOC 与锚点
在网页中生成的 TOC 往往是有交互功能的。哪怕是在 Word 文档中,自动生成的目录也是带有交互功能的域代码。这种交互就是单击对应的目录项目,跳转到文章中对应的位置的功能。在 HTML 中,这一点要通过锚点链接(anchor link)来实现。
在特定的语境中,锚点(anchor)指的是标记了页面中某个位置的一串 HTML 代码。要创建一个锚点,通常的做法是在元素上面附带 id 属性,此属性就是该锚点的标识符。该标识符的作用之一,是充当在 RFC 3986 中规定的 URI fragment(即常用的 document.hash 去掉 #),使得通过 URL 来标识一个页面中的子内容成为可能。这样的一个 URL 在实际应用上通常被称为 permalink(permanent link,永久链接)。
早期的锚点是通过 a 元素来实现的,具体写法是 <a name="..."></a>。把它放在需要锚定的位置,例如一个标题之前,就可以发挥相应的效果。很久以前就已经不这样写了。
Fun Facts:
a元素的名字就是 anchor。这是它本来的含义。而在现代语境下,a元素已经和超链接的概念强绑定了,主要依靠的是它的href(hyper reference)属性。- 接住上面的来说。由于
a元素在印象中就是超链接的意思,许多人认为它的href属性是必需的(required),所以会习惯性将空链接的href填为#。然而#本身的含义,只是一个空的 URI fragment,并非“哪里都不是”。这个href参数也是可带可不带。只有当a元素带有href时,才是严格意义上的超链接。
对于包含了 fragment 的 URL,浏览器的一个默认的行为就是将其对应的锚点元素移动到视口以内,这就是 TOC 运作的基础。
所以简单而言,在 HTML 中可用的 TOC 的一个表示,就是具有层级关系的一系列同页超链接(same-document hyperlinks),其中层级用于向用户反映这些链接之间关系,超链接则允许用户进行上文所提及的交互功能。自然,我们的 TOC 主要由 ul、li 和 a 三种元素构成。
做个调包侠
上面分析了那么多,其实都是后话。最开始我就打算直接调包使用。这是因为本博客所使用的 Markdown 解析库 markdown-it 的各种周边拓展都比较齐全,随便一搜就能找到,且大部分都是可用的。
我先删掉了停更四年之久的 markdown-it-toc-done-right 插件,然后转头去寻找更新的替代品,于是找到了这两个
它们必须搭配使用,因为 TOC 和 permalink 是相互联系的。于是我直接在 build.cjs 中添加了这两个包的引用,然后按照指示进行一些配置,就得到了一个带跳转功能的 TOC。然而我最终并没有采用,因为 markdown-it-table-of-contents 有着下面的限制:
- 位置不灵活:如果你只是希望文章的开头/结尾/某个位置能够有一个 TOC 存在,那么它的确能满足你的需求。但是我想要的是侧边的效果,所以还需要额外的 CSS 修改。
- 没有高亮:高亮并不是 TOC 的硬性需求,但是我还是希望有。这是没有采用它的根本原因。
- 不支持一些特殊的标题:这还是我的特殊需求 😋。在例如 Swift 学习笔记(一)——A Swift Tour、北疆之旅(一) 这样的文章中,常常有在标题元素里再加各种元素,如
img、code的用法,虽然不标准1,但可以让它们的显示效果更加丰富。这样的标题并不能被正确识别。
另外 markdown-it-anchor 也有一个限制:它不支持 Markdown 中自定义的 HTML 块的识别,所以 <h2>...</h2> 而非 ## ... 表示的二级标题会被忽略,相应的 permalink 也不会形成。这一点作者也在 README 中明确提到了。
于是我开始想着自己去实现一个简单的 TOC,只考虑两级标题:h2、h3。
自己实现一个 TOC
解析标题
构建 TOC 的一个很显然的方式,是提取出文档中所有的标题类元素(h1 等),然后将它们按照层级分类。markdown-it-table-of-contents 支持六级的配置,而我想做的简化版本只会考虑 h2、h3 这两级。至于 h1,为了 SEO 将它特许给了页面的大标题。
这个过程涉及到对文章页面编译出的 HTML 代码的解析和修改。考虑到性能,我决定将这个过程放在博客的编译环节。
看过本博客源码的都知道(谁看?),它是运作在本地 JSON 文件构成的文件数据库上的,一切数据都由 JavaScript 自带的 import json 功能从本地文件中获取。
虽然这样做很明显有性能问题(指文件读写方面),但是非常简单、稳定,也没遇到什么瓶颈,所以暂时没有考虑进行优化。
将逻辑放在编译环节的好处在于,这些运算只需要在编译阶段在编译机器上运行即可,而不需要由客户端来执行。那么具体应该怎样做呢?答案显然是正则表达式。由于我们想要的是提取标题标签之间的所有内容,所以初步构建的正则表达式是
<h2.*?>(.*?)<\/h2>
然而 . 并不包括换行符,所以经过测试替换成了 [\s\S],识别效果如下图。
 在 regex101.com 上面测试正则表达式
在 regex101.com 上面测试正则表达式
由于我们要处理的是 h2 和 h3,因此将正则表达式修改为
/<h(2|3).*?>([\s\S]*?)<\/h[23]>/
第一个组用来捕获该标签的层级,第二个组用于捕获它们之间的内容。然后就可以用下面的 JS 代码处理整个文本。
let m;
const headingRegex = /<h(2|3).*?>([\s\S]*?)<\/h[2-3]>/gm;
while ((m = headingRegex.exec(content)) !== null) {
// m[1] === '2' 或者 '3'
// m[2] === 内容
}
由于最后我们获取的是带有层级的数据,但只有两层,所以最终的结构类似于下面的 TypeScript 定义:
interface Heading {
text: string;
children: string[];
}
或者玩一下较为低级的类型体操,这样就可以实现多层的嵌套。
// 这里用 unknown 占位
type Enumerate<N extends number, T extends unknown[] = []> = T['length'] extends N ? T : Enumerate<N, [...T, unknown]>;
// 求后继
type Successor<N extends number> = [...Enumerate<N>, unknown]['length'] extends infer L ? (L extends number ? L : never) : never;
interface h<H extends number> {
level: H;
text: string;
children: H extends 6 ? [] : h<Successor<H>>;
}
由于正则表达式通常情况下是从前往后处理的,所以对于下面这个可能的序列
h2 h2 h3 h3 h3 h2 h3 h2 h2 h2 h3
我们会将从前一个 h2 开始,到后一个 h2 之间的所有 h3 都归纳为前一个 h2 的子项,最终形成的结构是:
h2:[] h2:[h3,h3,h3] h2:[h3] h2:[] h2:[] h2:[h3]
按照上面的分析,通过在 while 循环中 push 并用一个 ptr 来指示当前操作的 h2 的位置,就可以得到我们想要的数组了。
let ptr = -1;
let res = [];
while ((m = headingRegex.exec(content)) !== null) {
const level = m[1];
const text = m[2];
if (level === '2') {
res.push({
text,
children: []
});
ptr++;
}
if (level === '3') {
res[ptr].children.push(text);
}
}
这样我们就完成了对整个文章标题的解析,并形成了两层的结构。其实到这里,我们就已经可以呈现出 TOC 的大致框架了,只不过没有任何的交互。
<template>
<ul>
<li v-for="x in headings">
<a v-html="x.text" />
<ul v-if="x.children.length > 0">
<li v-for="y in x.children">
<a v-html="y" />
</li>
</ul>
</li>
</ul>
</template>
这里用到了 v-html,实现了插件无法所满足的显示复杂内容的功能。接下来,我们需要为这些 a 标签添加 href 属性,使得它们可以交互。这就涉及到前文所提到的锚点。有了标识符,就有了锚点,该如何选择呢?
构造锚点标识符
锚点标识符本质上就是一个字符串,用于唯一标识一个锚点,在这里是标题。
锚点标识符一般是由锚点的内容所决定的(因为这是确保其“唯一”最简单的依据)。人们在阅读文章时,专注的是其内容,因而对于一个标题的 permalink,我们希望其可读性高一些。对这一点继续加以考虑,就形成了普遍使用的一种锚点标识符模式,称之为 slugification(slug 也有蛞蝓 🐌 的意思)。Slug 的好处很明显:人类可读(human-readable),SEO 自然也良好。
但这些都是基于英文的理想化考虑。受制于 URL 自身的标准,对于非 ASCII 字符,这些需求就显得苍白无力了。而且我们并不能将中文原封不动地塞进 slug 里面。
为此,人们想出了利用拉丁转写、去除注音符号等方法,来实现非 ASCII 字符的 slugification。markdown-it-anchor 的作者推荐了 sindresorhus/slugify,这是一个用来将不同语言的内容转化为 slug 的库,其本质操作就是前面所提到的两点:转写和去除。下面是它的使用例子:
import slugify from '@sindresorhus/slugify';
slugify('I ♥ Dogs');
//=> 'i-love-dogs'
slugify(' Déjà Vu! ');
//=> 'deja-vu'
slugify('fooBar 123 $#%');
//=> 'foo-bar-123'
slugify('я люблю единорогов');
//=> 'ya-lyublyu-edinorogov'
可以看到
♥这种特殊符号,被代表其含义的英文单词love所替换。- 带有注音、着重等修饰符的字母,其修饰符被去掉,例如
Déjà Vu(法语)被替换成deja-vu - 无明确含义的特殊符号,如
$#%被直接去掉。这个库也提供了自定义的替换方案,所以你可以定制地将$替换成dollar-sign、#替换成hashtag、%替换成percentage等有意义的字符串。 - 西里尔文被替换成了对应的拉丁转写
遗憾的是这个库并不支持中文,相关的讨论在 sindresorhus/transliterate 的第一个 Issue 里。在这里他们提出了用拼音、拼音加上数字注音、加上笔画数等来防止混淆,甚至还有人用 GPT 来为中文标题生成一个英文的 slug(这样就不需要考虑中文的处理了),等等,但至今仍然没有得出结论,也没有实现(这是 2018 年的 Issue)。
 难绷
难绷
那么能否回归本真,用 URI encoding 的形式来呈现中文呢?理论上是可行的,但是实际上很难获得良好的 SEO 和用户认知体验。本博客现在使用的 slugify 函数就来自于 markdown-it-anchor 中,用 substring 限制了长度。
const slugify = s => encodeURIComponent(String(s).trim().toLowerCase().replace(/\s+/g, '-').substring(0, 50));
这个函数将传入的参数进行简单的变换(去除首尾空格、转小写、将空格转换为 - 等),再将其进行 URI encoding。前面提到的编码过程的可行性在于,当通过相应的锚点链接访问时,浏览器的默认行为会将这些经过 URI encoding 的文本再原样呈现在地址中,例如“你好”在编码后呈现为 %E4%BD%A0%E5%A5%BD,当用浏览器访问带有这一 fragment 的 URL 时,它会被自动呈现为“你好”。这是一种很自然的过程,也符合人类的认知。
但是,如果我们希望将其作为一个中文特有的 slugify 方式投入到实际应用,又显得不可行了,因为它必须具有面向用户的广泛支持才行。而在 QQ 上发布一条带有含中文的 URL https://baidu.com/s?wd=搜索中文 的消息, QQ 只能识别到 https://baidu.com/?s=,后面的中文会被抛弃。所以这种最具有辨识性也最简单的方式,反而并不可行,至少在一些软件支持之前,并不能作为一种有效的中文 slugify 方式。
我测试了四款软件,相关的支持情况如下。
| 软件 | 是否支持 URL 中文 | 截图 |
|---|---|---|
| 微信 | 否 |  |
| 否 |  | |
| VSCode | 是 |  |
| Telegram | 是 |  |
当然,如果只靠 URI encoding 也并不足够,例如本博客的需求。还需要进行一些额外处理来消去其中对用户没有意义的字符,否则就会呈现像这样的 URL:
 开心就好
开心就好
除此之外,还有一种更妥协的方式,即不考虑 slugify 以及由此诞生的 SEO 议题,而是直接随机生成/按照一定内容来生成标识符,例如哔哩哔哩的 BV 号,以及 YouTube 的视频链接地址。
回到我们的主题上来。引入了 slugify 函数后,我们就可以为每一个标题创建一个 permalink。对编译以后的 HTML 执行以下操作,就将其包装为了一个带 permalink 的标题。
for (const h of document.querySelectorAll('h2, h3')) {
const slug = slugify(h.innerHTML);
h.setAttribute('id', slug);
const wrapper = document.createElement('div');
wrapper.classList.add('header-wrapper');
wrapper.innerHTML = `<${h.tagName.toLowerCase()} id="${slug}" tabindex="-1">${h.innerHTML}</${h.tagName.toLowerCase()}><a class="header-anchor" href="#${slug}"><span aria-hidden="true">${HEADING_SYMBOL}</span></a>`;
console.log(`Built slug ${slug}.`);
h.parentNode.replaceChild(wrapper, h);
}
有了 permalink 以后,再修改 TOC 的相关代码,就得到了具有交互的 TOC。
<template>
<ul>
<li v-for="x in headings">
<a v-html="x.text" :href="x.slug" />
<ul v-if="x.children.length > 0">
<a v-html="y.text" :href="y.slug" />
</ul>
</li>
</ul>
</template>
while ((m = headingRegex.exec(content)) !== null) {
const level = m[1];
const text = m[2];
if (level === '2') {
res.push({
text,
slug: slugify(text), // [!code ++]
children: []
});
ptr++;
}
if (level === '3') {
res[ptr].children.push({
text,
slug: slugify(text) // [!code ++]
});
}
}
有了交互功能后,下一步要考虑的是高亮,也就是页面滑到哪里,哪一个 TOC 项目就会亮起来的效果。
为 TOC 添加高亮
视口检测
在进行高亮的相关逻辑的编写之前,我们需要先实现对元素的视口检测。元素是否在视口中,可以通过元素自带的 bounding rect(边界矩形)来判断。这个矩形的相关参数如下图。
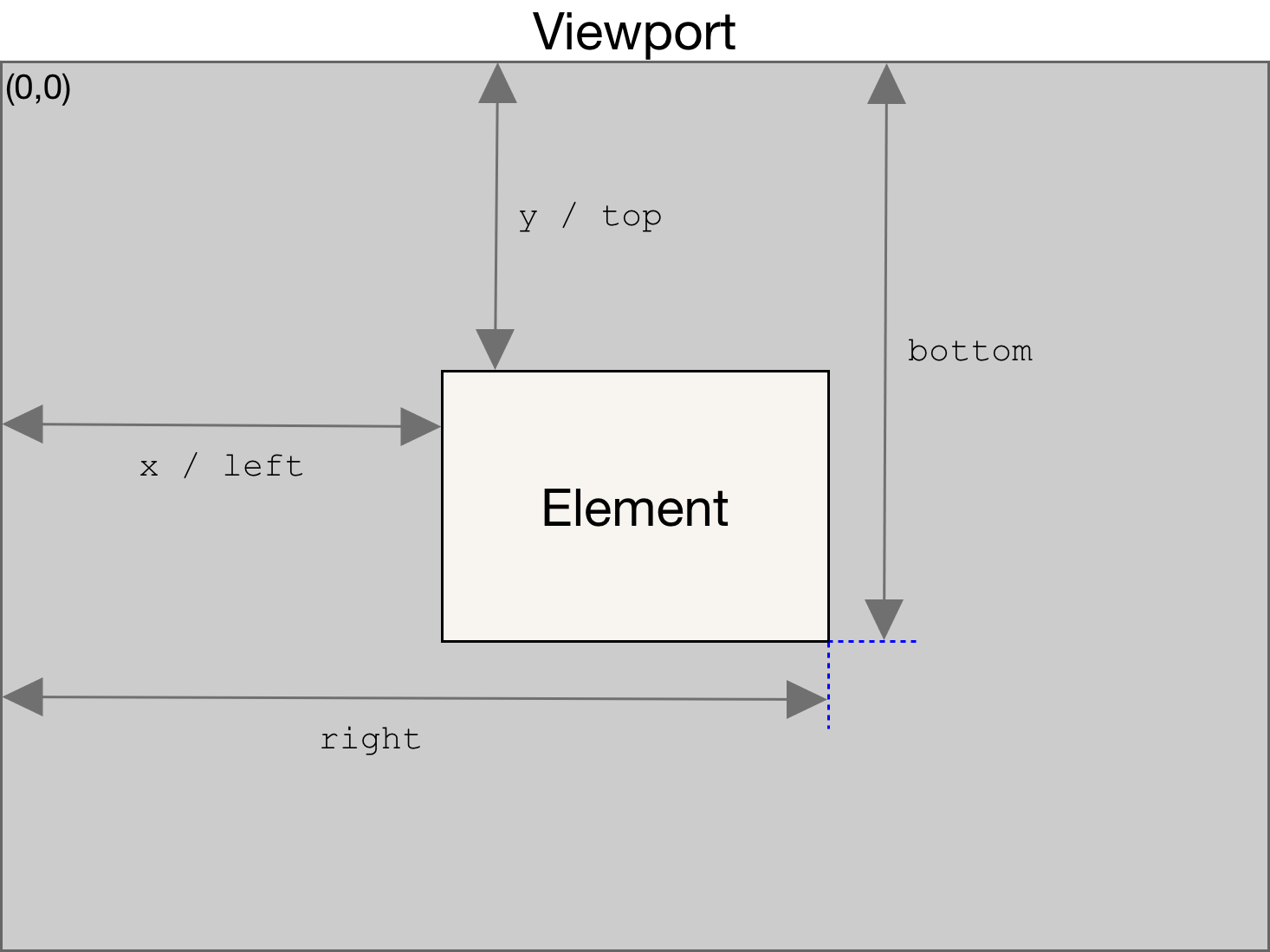 图源 mozzila.org - 元素的 Bounding Rect 示意
图源 mozzila.org - 元素的 Bounding Rect 示意
所以判断元素是否在视口中,就是判断其 bounding rect 的 top、left、bottom、right 四个参数是否满足一定的条件。由此可直接给出判断元素是否在视口中的函数:
function isElementInViewport(el) {
const rect = el.getBoundingClientRect();
return rect.top >= 0 && rect.left >= 0 && rect.bottom <= window.innerHeight && rect.right <= window.innerWidth;
}
以标题为标志物
一个通常的想法是,以标题为标志物。
基本逻辑是,当页面滚动到某个标题的位置时(该标题在视口中),相应的 TOC 项目就亮起来。在应用中常常会遇到有多个标题存在的情况,这时要么选择只高亮第一个或者最后一个,要么都高亮。为了符合直觉通常会选择前面两种方案。这样带来的问题很明显
- 由于我们以标题为标志物,当页面中的某些内容过长而导致视口中没有标题时,就没有 TOC 项目亮起来。
- 无论是上翻还是下翻,TOC 项目亮起的时机总是由某个标题的进入和离开所决定的。
但是,按照直觉,亮起的 TOC 项目应该指示的是当前正在阅读的内容,而非标题。因此,以标题为标志物并不恰当。
以内容为标志物
了解到把标题作为标志物并不恰当以后,考虑以内容为标志物。
如果我们可以获取到内容元素所属的标题,就可以推断出当前视口中所存在的不同标题下的内容元素数量,进而得到它们的占比,从而得出当前视口中呈现的主要内容所属的标题,这正是一种符合直觉的高亮选择。接下来,探讨如何为元素附加标题的相关信息。
为元素附加所属标题
经过 markdown-it 编译后,文章的元素从上到下大致是这样的:
h2 p p p h2 h3 p p table p p h3 p pre p h2 p p p
在前面提到,h3 永远是 h2 的子项目,所以我们可以认为两个 h2 之间的 h3 都属于前一个 h2。在这里讨论的是具体的内容元素(如 p、pre、table),我们可以认为两个 h 之间的内容都属于前一个 h。为了能够高效地获取到这些内容,并且为它们附加正确的标题数据,联想到使用 CSS 选择器。
虽然 CSS 选择器并没有直接表示两个元素之间的语法,却可以用逻辑将这种特殊的选择器表示出来,参考 StackOverflow - How to select all elements between two elements?。
#first ~ :not( #second ~ * ):not( #second )
只需将 #first 替换成前一个标题的选择器,#second 替换成后一个标题的选择器,就可以选择到归属于前一个标题的所有内容元素(同时不包括后一个标题本身),再在它们上面附加前一个标题的相关信息就可以达到目的。
这里用到 ~,是考虑到标题和内容元素应当是同级的。我们在构造锚点标识符并附加 permalink 时,对这些标题进行了包装,其具体呈现是一个包含有 h 元素、相关图标等元素的 div,所以 #first、#second 处所填的并非是 h2 或者 h3,而是带有类似于 :has(h2) 的选择器。
为了得到这样的选择器,需要用到我们先前构建出来的 headings 数据。前面的这一数据是带有层级结构的。此处根据上面的推理,并不需要这种层级,只需将这些标题按照正确的顺序,从前往后排列成一个一维数组。这一过程代码如下:
const headingsFlat = headings
.map(x => [
{ h: 2, text: x.text, slug: x.slug },
...x.children.map(y => {
return { h: 3, text: y.text, slug: y.slug };
})
])
.flat();
我们实现了下面的转换:
{
"text": "标题 2",
"slug": "slug-2",
"children": [
{
"text": "标题 3 1",
"slug": "slug-3-1"
},
{
"text": "标题 3 2",
"slug": "slug-3-2"
}
]
}
=>
[{"h": 2, "text": "标题 2", "slug": "slug-2"}, {"h": 3, "text": "标题 3 1", "slug": "slug-3-1"}, {"h": 3, "text": "标题 3 2", "slug": "slug-3-2"}]
将这一结构与上面的选择器模板结合,就得到了选择相关内容元素的有力工具。在正确选择到这些元素之后,通过 setAttribute 附加相关内容,就完成了为元素附加所属标题的步骤。这样做的意义很明显:我们可以快速地选择到当前视口中属于某一个标题的一群元素,并进行一些统计了。
for (let i = 0; i < headingsFlat.length - 1; i++) {
const thisOne = headingsFlat[i];
const nextOne = headingsFlat[i + 1];
const selector = '#1 ~ :not( #2 ~ * ):not( #2 )'.replace('#1', `.heading-wrapper:has(h${thisOne.h}[id="${thisOne.s}"])`).replace(/#2/g, `.heading-wrapper:has(h${nextOne.h}[id="${nextOne.s}"])`);
for (const el of document.querySelectorAll(selector)) {
el.setAttribute('data-section', thisOne.s);
}
}
// 以上代码未处理最后一个标题元素之后的内容元素
// 相关代码略
确定浏览位置
通过下面的代码可以获取到当前视口中所有的内容元素。
const viewportElements = Array.from(document.querySelectorAll('[data-section]')).filter(el => isElementInViewport(el));
有了上面的标记,可以很容易地计算出一些相关的指标。
- 当前视口中各部分元素的占比
- 当前视口中各部分元素的高度占比
- 当前视口中各部分元素的宽度占比
- ...
其中前两个指标最为重要,它们的计算也很简单。例如第一个指标的计算方法如下:
// 获取代表相关页面区域的字符串,在这里就是 slug 的内容
const viewportSectionNames = viewportElements.map(y => y.getAttribute('data-section'));
// 统计当前视口中存在的每一个 slug 对应的元素总数或者比例
const uniqueNamePortions = viewportSectionNames
.filter((x, i) => viewportSectionNames.indexOf(x) === i)
.map(u => {
let n = viewportSectionNames.filter(x => x === u).length;
return {
s: u,
n,
p: n / viewportElements.length
};
});
事实证明这一指标还无法正确反映当前用户视口的“主要内容”,因为没有考虑观感上的因素。所以我们可以考虑使用第二个指标,计算元素的高度占比。
const viewportSectionNames = viewportElements.map(y => y.getAttribute('data-section'));
const uniqueNamePortions = viewportSectionNames.filter((x, i) => viewportSectionNames.indexOf(x) === i).map(u => {
let n = viewportSectionNames.filter(x => x === u).length; // [!code --]
let n = viewportElements.filter(el => el.getAttribute('data-section') === u).reduce((a, b) => a + b.clientHeight, 0); // [!code ++]
return {
s: u,
n,
p: n / viewportElements.length // [!code --]
// window.innerHeight 也可以替换为视口内容元素 height 之和 // [!code ++]
p: n / window.innerHeight // [!code ++]
}
})
目前博客使用的正是这一指标。再通过一些算法从中选择出占比最大的那个(如果相同,就选择靠下面的那个)viewport section name(在这里也就是 slug),通过 CSS 选择器顺藤摸瓜就可以获取到相应的 TOC 项目,完成高亮的选择。
注释
-
正如文中“构造锚点标识符”部分的内容所述,这样做会导致 slugify 的过程需要额外考虑对这些标签的处理来增加可读性,如不做处理则会让 URL 显得比较混乱(中间带有 HTML 标签)。 ↩